
손실 함수 (Loss Function)와 경사 하강법 (Gradient Descent)
10 Mar 2020 | Deep-Learning
Learning
신경망(Neural net)은 파라미터를 더 좋은 방향으로 개선하도록 학습해나갑니다. 여기서 ‘더 좋은 방향’이란 무엇일까요? 우리가 길을 갈 때에도 목적지를 정하고 그 방향대로 나아가야 하듯 신경망에게도 나아가야 하는 ‘방향’이 있습니다. 이 때 방향을 결정하는 기준이 되는 것이 바로 손실 함수(Loss function)입니다. 이번 시간에는 손실 함수에 대해서 알아보도록 하겠습니다.
Loss function
신경망 노드 내의 파라미터가 어느 방향으로 개선되어야 할 지 판단하는 지표로 손실(Loss, Cost)을 사용합니다. 어떤 작업을 수행할 지에 따라 손실을 구하기 위한 손실 함수(Loss function, Cost function)이 달라집니다.
Mean Square Error (MSE)
회귀(Regression)에서는 손실 함수로 대개 평균 제곱 오차(Mean square error, MSE)를 사용합니다. 평균 제곱 오차는 실제 값과 예측값의 차이를 구한 뒤 제곱한 값을 모든 인스턴스에 대해 더한 것입니다. 아래는 평균 제곱 오차의 수식입니다.
\[\text{Loss}_{MSE} = \frac{1}{2}\sum_k{(\hat{y}_k - y_k)^2}\]
위 식에서 $\hat{y}_k$는 신경망이 출력하는 값, 즉 예측값입니다. $y_k$는 실제 데이터가 가지고 있는 레이블입니다. $k$는 데이터의 개수입니다. 아래는 각 인스턴스에 대해 평균 제곱 오차를 시각화하여 나타낸 것입니다. 아래 이미지에서 빨간 막대의 길이를 제곱한 뒤 모두 더해준 값을 반으로 나눈 값이 평균 제곱 오차값이 됩니다.
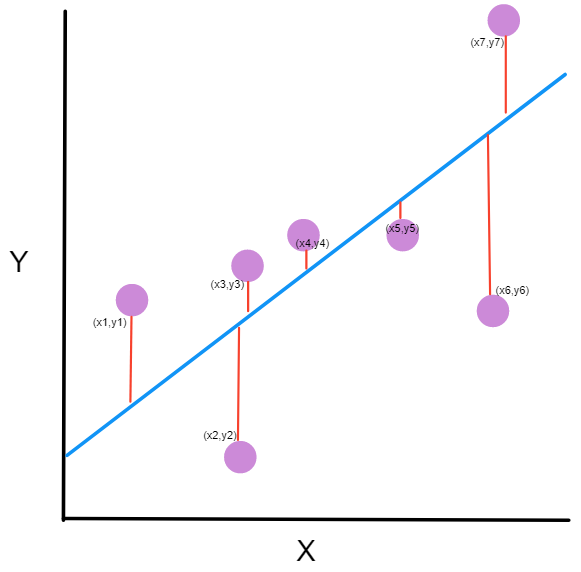
이미지 출처 : freecodecamp.org
평균 제곱 오차는 직관적이고 이해하기 쉽습니다. 도함수 식의 계산도 쉽기 때문에 회귀의 손실 함수로 주로 사용됩니다.
Cross-Entropy Error
이진 분류(Classification)에서는 교차 엔트로피 오차(Cross-entropy error, CEE)를 주로 사용합니다. 교차 엔트로피 오차를 사용하여 구한 오차를 수식으로 나타내면 아래와 같습니다.
\[\text{Loss}_{CEE} = -\sum_k{y_k\log_2{\hat{y}_k}}\]
교차 엔트로피 오차는 어떻게 작용할까요? 실제 레이블이 $\left[\begin{array}{ccccc}1 & 0 & 0 & 0 & 0\end{array}\right]$ 인 5개의 인스턴스에 대하여 2개의 분류기가 각각 다음과 같이 예측값을 내놓았다고 가정하겠습니다.
\[\text{Classifier 1} : \left[\begin{array}{ccccc}1 & 0 & 0 & 0 & 0\end{array}\right]\\
\text{Classifier 2} : \left[\begin{array}{ccccc}0 & 0 & 0 & 0 & 0\end{array}\right]\]
분류기1은 실제 레이블과 동일한 예측값을 내놓았습니다. 하지만 분류기2는 하나의 인스턴스에 대해 잘못 예측했네요. 각 분류기에 대해 교차 엔트로피 오차를 구해보겠습니다. ( $\log_2 0 = -\infty$ 이므로 $0$ 대신 매우 작은 값인 $2^{-10^{10}}$을 대입하여 $\log_2 2^{-10^{10}} = -10^{10}$으로 대체하겠습니다.)
\[\begin{aligned}
L_1 &= -(1\log1 + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}}) \\
&= - (1\cdot 0 + 0\cdot -10^{10} +0\cdot -10^{10}+0\cdot -10^{10}+0\cdot -10^{10})= 0 \\
L_2 &= -(1\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}}) \\
& = - (1\cdot -10^{10} + 0\cdot -10^{10} +0\cdot -10^{10}+0\cdot -10^{10}+0\cdot -10^{10})= 10^{10}
\end{aligned}\]
레이블을 모두 맞춘 첫 번째 분류기의 교차 엔트로피 오차는 $0$ 이 나옵니다. 하지만 하나를 틀린 두 번째 분류기의 교차 엔트로피 오차는 매우 큰 값이 나왔습니다. 교차 엔트로피 오차의 식에는 로그 함수 $\log_2x$ 가 있습니다. 로그 함수는 $0$으로 갈 때 급격하게 값이 $-\infty$로 발산하는 특성이 있습니다. 교차 엔트로피 오차는 이런 특성을 사용하여 레이블을 잘못 예측했을 때 엄청 큰 손실 값을 배정합니다. 아래는 로그 함수의 그래프입니다.
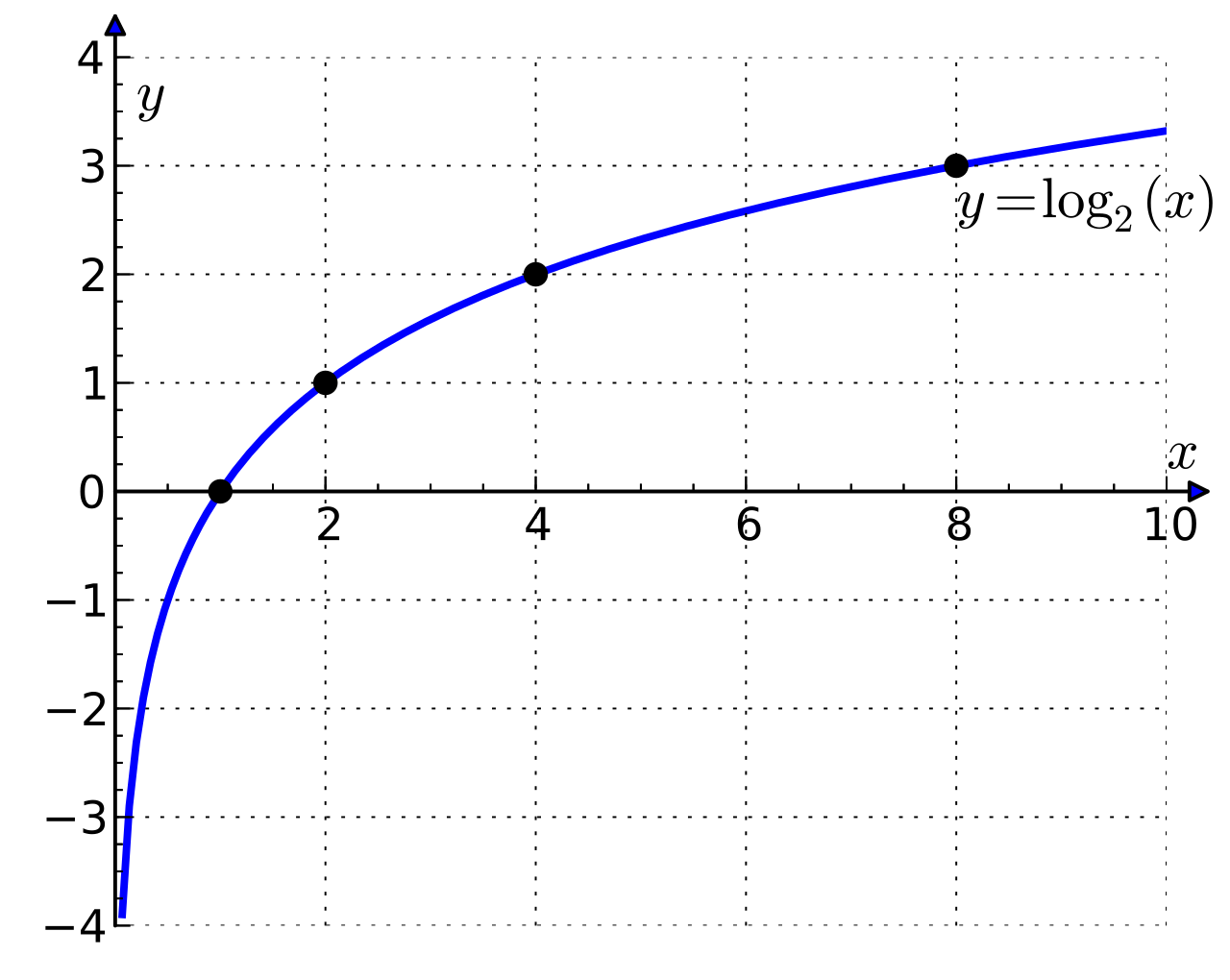
이미지 출처 : wikipedia - Logarithm
Gradient Descent
손실 함수의 값은 말 그대로 손실(Loss)입니다. 이 값이 크면 신경망 모델의 성능이 좋지 않다는 뜻입니다. 그렇기 때문에 학습은 손실 함수의 값을 줄이는 방향으로 진행해야 하지요. 신경망에서는 파라미터를 개선하는 방법으로 경사 하강법(Gradient descent method)을 사용합니다.
Gradient
경사 하강법이 뭐길래 손실 함수의 값을 낮추기 위해 이 방법을 사용하는 것일까요? 실제 고차원 데이터를 다룰 때 손실 함수의 그래프는 아래와 같이 생겼습니다. 손실 함수의 최솟값은 아래 그림에서 가장 낮은 지점이 됩니다. 이 지점을 찾기 위해서 점점 아래로 구슬이 굴러가듯 경사를 따라 내려가는데 이를 경사 하강법이라고 합니다.
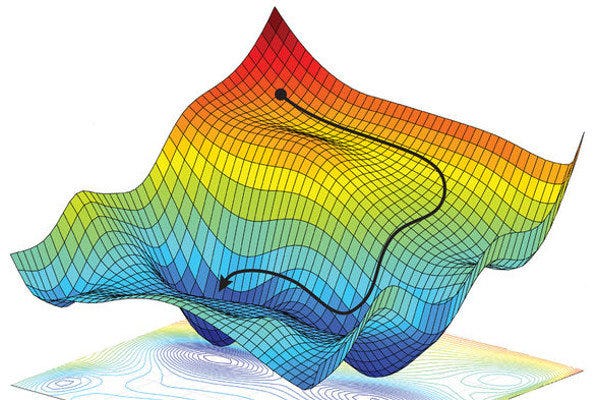
이미지 출처 : medium.com
경사 하강법을 하려면 우선 경사(기울기)를 먼저 알아야겠죠. 경사는 미분을 사용하여 구합니다. 임의의 미분가능한 함수 $f(x)$의 도함수는 다음과 같이 구할 수 있습니다.
\[\frac{df(x)}{dx} = \lim_{h \rightarrow 0} \frac{f(x+h)-f(x)}{h}\]
변수가 2개 이상일 때는 편미분(Partial derivative)을 사용합니다. 편미분은 특정 변수 하나에 초점을 맞추어 미분을 하는 방식입니다. 다른 모든 변수는 상수로 취급하고 일변수 함수의 미분 방법을 적용합니다. 간단한 예를 들어보겠습니다. 다변수 함수 $g(x, y, z) = 3 x^2 y + x y^2 z + 2x + yz$ 가 있다고 해보겠습니다. 이를 $x$ 에 대해 편미분하면 다음과 같은 식이 도출됩니다.
\[\frac{\partial g(x,y,z)}{\partial x} = 6xy + y^2z + 2\]
손실 함수의 변수가 여러 개일 때 각 변수에 대한 편미분을 벡터로 묶어 정리한 것을 그래디언트(Gradient)라고 합니다. 예를 들어, $h(x_1, x_2, \cdots, x_n)$ 과 같이 변수가 $n$ 개인 함수의 그래디언트는 다음과 같이 나타나게 됩니다.
\[\nabla_x h(x) = \bigg[\frac{\partial h(x)}{\partial x_1}, \frac{\partial h(x)}{\partial x_2}, \cdots, \frac{\partial h(x)}{\partial x_n}\bigg]\]
Descent
그래디언트를 알았으니 이제 하강(Descent)을 알아볼 시간입니다. 실제로 맞닥뜨리는 손실 함수는 부분적으로 컨벡스(Convex, 볼록) 함수입니다. 컨벡스 함수가 무엇인지는 아래의 그래프를 통해서 알아보겠습니다.

이미지 출처 : wikipedia - convex function
2차원 평면상에서 컨벡스 함수 $f(x)$는 다음의 조건을 만족합니다. $f(x)$ 위의 두 점 $(x_1, f(x_1)), (x_2, f(x_2))$ 을 잇는 직선을 $g(x)$ 라 하겠습니다. 이 때, 구간 $(x_1, x_2)$ 사이의 점 $x_m$ 에서 $f(x) < g(x)$ 입니다. 3차원 컨벡스 함수는 어떻게 생겼을까요? 아래에 3차원 컨벡스 함수가 있습니다.
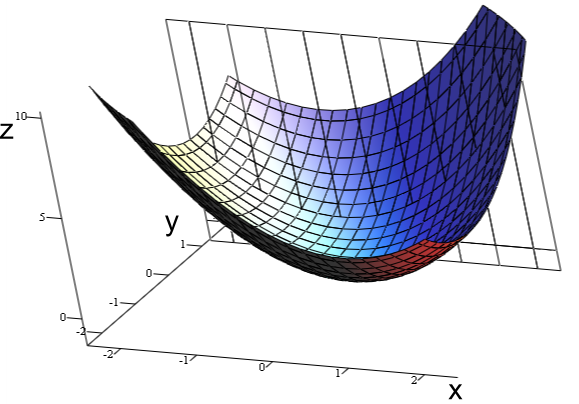
이미지 출처 : wikipedia - convex function
우리 목적은 구슬이 굴러 내려가듯 내리막길을 따라 최저점(Minimum)에 다다르는 것이었습니다. 컨벡스 함수에서는 어떤 점에서 시작하더라도 내리막으로만 움직인다면 최저점에 도착할 수 있지요. 함수 $f(x)$의 기울기를 따라 내려가는 과정, 즉 경사 하강법을 수식으로 나타내면 다음과 같습니다. 아래 식에서는 변수 $x_i$ 에 대해서 편미분한 기울기만을 사용하였습니다.
\[x_{i,j+1} := x_{i,j} - \eta \frac{\partial f(x)}{\partial x_{i,j}}\]
구슬이 굴러가는 비유대신 한 발짝씩 산을 내려가는 과정으로 생각해보겠습니다. 위 식에서 좌변에 있는 $x_{i,j+1}$ 는 새로 발을 내딛을 위치입니다. 우변에 있는 $x_i$ 는 현재 자신이 서있는 위치입니다. $\frac{\partial f(x)}{\partial x_i}$ 는 그 위치에서의 기울기가 되겠지요. 우리는 내려가야 하므로 원래 위치 $x_{i,j}$ 에 기울기를 빼주어 새로운 위치 $x_{i,j+1}$ 을 정하게 됩니다.
그렇다면 $\eta$ 는 무엇일까요? $\eta$ 는 학습률(Learning rate)입니다. 이 하이퍼파라미터(Hyperparameter)는 기울기를 따라 얼마만큼 내려갈지를 결정합니다. 이 값이 너무 작으면 최저점을 찾아가는데 오랜 시간을 필요로합니다. 심한 경우에는 주어진 반복(iteration) 내에서 최저점을 찾지 못하기도 하지요. 반대로 학습률이 너무 크면 최저점을 지나쳐버립니다. 제대로 된 학습을 하지 못하거나 발산해버리는 문제가 발생하지요.
반지름이 1m인 구덩이가 있을 때, 개미와 공룡이 이 구덩이의 최저점을 향해 나아간다고 생각해보겠습니다. 개미가 중심까지 가려면 엄청 오랜 시간이 걸릴 것이고, 공룡은 중심을 지나보지도 못하고 휙 지나쳐 버리겠지요. 아래는 학습률이 너무 작을 때와 클 때 $x_j$ 가 어떻게 변하는지를 보여주는 이미지입니다.
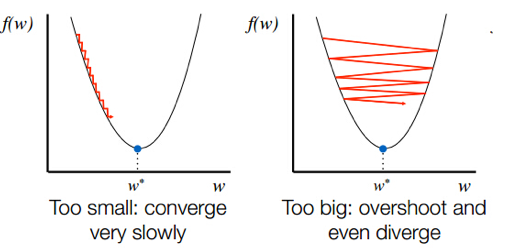
이미지 출처 : srdas.github.io
제대로된 학습을 위해서는 적절한 학습률 찾아야만 합니다. 그렇기 때문에 처음에는 큰 학습률을 사용하다가 점점 줄이는 학습률 감쇠(Learning rate decay) 등의 다양한 전략을 사용합니다. 이곳에서 경사 하강법에 대한 더 자세히 알아볼 수 있습니다.
Learning
신경망(Neural net)은 파라미터를 더 좋은 방향으로 개선하도록 학습해나갑니다. 여기서 ‘더 좋은 방향’이란 무엇일까요? 우리가 길을 갈 때에도 목적지를 정하고 그 방향대로 나아가야 하듯 신경망에게도 나아가야 하는 ‘방향’이 있습니다. 이 때 방향을 결정하는 기준이 되는 것이 바로 손실 함수(Loss function)입니다. 이번 시간에는 손실 함수에 대해서 알아보도록 하겠습니다.
Loss function
신경망 노드 내의 파라미터가 어느 방향으로 개선되어야 할 지 판단하는 지표로 손실(Loss, Cost)을 사용합니다. 어떤 작업을 수행할 지에 따라 손실을 구하기 위한 손실 함수(Loss function, Cost function)이 달라집니다.
Mean Square Error (MSE)
회귀(Regression)에서는 손실 함수로 대개 평균 제곱 오차(Mean square error, MSE)를 사용합니다. 평균 제곱 오차는 실제 값과 예측값의 차이를 구한 뒤 제곱한 값을 모든 인스턴스에 대해 더한 것입니다. 아래는 평균 제곱 오차의 수식입니다.
\[\text{Loss}_{MSE} = \frac{1}{2}\sum_k{(\hat{y}_k - y_k)^2}\]위 식에서 $\hat{y}_k$는 신경망이 출력하는 값, 즉 예측값입니다. $y_k$는 실제 데이터가 가지고 있는 레이블입니다. $k$는 데이터의 개수입니다. 아래는 각 인스턴스에 대해 평균 제곱 오차를 시각화하여 나타낸 것입니다. 아래 이미지에서 빨간 막대의 길이를 제곱한 뒤 모두 더해준 값을 반으로 나눈 값이 평균 제곱 오차값이 됩니다.
이미지 출처 : freecodecamp.org
평균 제곱 오차는 직관적이고 이해하기 쉽습니다. 도함수 식의 계산도 쉽기 때문에 회귀의 손실 함수로 주로 사용됩니다.
Cross-Entropy Error
이진 분류(Classification)에서는 교차 엔트로피 오차(Cross-entropy error, CEE)를 주로 사용합니다. 교차 엔트로피 오차를 사용하여 구한 오차를 수식으로 나타내면 아래와 같습니다.
\[\text{Loss}_{CEE} = -\sum_k{y_k\log_2{\hat{y}_k}}\]교차 엔트로피 오차는 어떻게 작용할까요? 실제 레이블이 $\left[\begin{array}{ccccc}1 & 0 & 0 & 0 & 0\end{array}\right]$ 인 5개의 인스턴스에 대하여 2개의 분류기가 각각 다음과 같이 예측값을 내놓았다고 가정하겠습니다.
\[\text{Classifier 1} : \left[\begin{array}{ccccc}1 & 0 & 0 & 0 & 0\end{array}\right]\\ \text{Classifier 2} : \left[\begin{array}{ccccc}0 & 0 & 0 & 0 & 0\end{array}\right]\]분류기1은 실제 레이블과 동일한 예측값을 내놓았습니다. 하지만 분류기2는 하나의 인스턴스에 대해 잘못 예측했네요. 각 분류기에 대해 교차 엔트로피 오차를 구해보겠습니다. ( $\log_2 0 = -\infty$ 이므로 $0$ 대신 매우 작은 값인 $2^{-10^{10}}$을 대입하여 $\log_2 2^{-10^{10}} = -10^{10}$으로 대체하겠습니다.)
\[\begin{aligned} L_1 &= -(1\log1 + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}}) \\ &= - (1\cdot 0 + 0\cdot -10^{10} +0\cdot -10^{10}+0\cdot -10^{10}+0\cdot -10^{10})= 0 \\ L_2 &= -(1\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}} + 0\cdot \log 2^{-10^{10}}) \\ & = - (1\cdot -10^{10} + 0\cdot -10^{10} +0\cdot -10^{10}+0\cdot -10^{10}+0\cdot -10^{10})= 10^{10} \end{aligned}\]레이블을 모두 맞춘 첫 번째 분류기의 교차 엔트로피 오차는 $0$ 이 나옵니다. 하지만 하나를 틀린 두 번째 분류기의 교차 엔트로피 오차는 매우 큰 값이 나왔습니다. 교차 엔트로피 오차의 식에는 로그 함수 $\log_2x$ 가 있습니다. 로그 함수는 $0$으로 갈 때 급격하게 값이 $-\infty$로 발산하는 특성이 있습니다. 교차 엔트로피 오차는 이런 특성을 사용하여 레이블을 잘못 예측했을 때 엄청 큰 손실 값을 배정합니다. 아래는 로그 함수의 그래프입니다.
이미지 출처 : wikipedia - Logarithm
Gradient Descent
손실 함수의 값은 말 그대로 손실(Loss)입니다. 이 값이 크면 신경망 모델의 성능이 좋지 않다는 뜻입니다. 그렇기 때문에 학습은 손실 함수의 값을 줄이는 방향으로 진행해야 하지요. 신경망에서는 파라미터를 개선하는 방법으로 경사 하강법(Gradient descent method)을 사용합니다.
Gradient
경사 하강법이 뭐길래 손실 함수의 값을 낮추기 위해 이 방법을 사용하는 것일까요? 실제 고차원 데이터를 다룰 때 손실 함수의 그래프는 아래와 같이 생겼습니다. 손실 함수의 최솟값은 아래 그림에서 가장 낮은 지점이 됩니다. 이 지점을 찾기 위해서 점점 아래로 구슬이 굴러가듯 경사를 따라 내려가는데 이를 경사 하강법이라고 합니다.
이미지 출처 : medium.com
경사 하강법을 하려면 우선 경사(기울기)를 먼저 알아야겠죠. 경사는 미분을 사용하여 구합니다. 임의의 미분가능한 함수 $f(x)$의 도함수는 다음과 같이 구할 수 있습니다.
\[\frac{df(x)}{dx} = \lim_{h \rightarrow 0} \frac{f(x+h)-f(x)}{h}\]변수가 2개 이상일 때는 편미분(Partial derivative)을 사용합니다. 편미분은 특정 변수 하나에 초점을 맞추어 미분을 하는 방식입니다. 다른 모든 변수는 상수로 취급하고 일변수 함수의 미분 방법을 적용합니다. 간단한 예를 들어보겠습니다. 다변수 함수 $g(x, y, z) = 3 x^2 y + x y^2 z + 2x + yz$ 가 있다고 해보겠습니다. 이를 $x$ 에 대해 편미분하면 다음과 같은 식이 도출됩니다.
\[\frac{\partial g(x,y,z)}{\partial x} = 6xy + y^2z + 2\]손실 함수의 변수가 여러 개일 때 각 변수에 대한 편미분을 벡터로 묶어 정리한 것을 그래디언트(Gradient)라고 합니다. 예를 들어, $h(x_1, x_2, \cdots, x_n)$ 과 같이 변수가 $n$ 개인 함수의 그래디언트는 다음과 같이 나타나게 됩니다.
\[\nabla_x h(x) = \bigg[\frac{\partial h(x)}{\partial x_1}, \frac{\partial h(x)}{\partial x_2}, \cdots, \frac{\partial h(x)}{\partial x_n}\bigg]\]Descent
그래디언트를 알았으니 이제 하강(Descent)을 알아볼 시간입니다. 실제로 맞닥뜨리는 손실 함수는 부분적으로 컨벡스(Convex, 볼록) 함수입니다. 컨벡스 함수가 무엇인지는 아래의 그래프를 통해서 알아보겠습니다.
이미지 출처 : wikipedia - convex function
2차원 평면상에서 컨벡스 함수 $f(x)$는 다음의 조건을 만족합니다. $f(x)$ 위의 두 점 $(x_1, f(x_1)), (x_2, f(x_2))$ 을 잇는 직선을 $g(x)$ 라 하겠습니다. 이 때, 구간 $(x_1, x_2)$ 사이의 점 $x_m$ 에서 $f(x) < g(x)$ 입니다. 3차원 컨벡스 함수는 어떻게 생겼을까요? 아래에 3차원 컨벡스 함수가 있습니다.
이미지 출처 : wikipedia - convex function
우리 목적은 구슬이 굴러 내려가듯 내리막길을 따라 최저점(Minimum)에 다다르는 것이었습니다. 컨벡스 함수에서는 어떤 점에서 시작하더라도 내리막으로만 움직인다면 최저점에 도착할 수 있지요. 함수 $f(x)$의 기울기를 따라 내려가는 과정, 즉 경사 하강법을 수식으로 나타내면 다음과 같습니다. 아래 식에서는 변수 $x_i$ 에 대해서 편미분한 기울기만을 사용하였습니다.
\[x_{i,j+1} := x_{i,j} - \eta \frac{\partial f(x)}{\partial x_{i,j}}\]구슬이 굴러가는 비유대신 한 발짝씩 산을 내려가는 과정으로 생각해보겠습니다. 위 식에서 좌변에 있는 $x_{i,j+1}$ 는 새로 발을 내딛을 위치입니다. 우변에 있는 $x_i$ 는 현재 자신이 서있는 위치입니다. $\frac{\partial f(x)}{\partial x_i}$ 는 그 위치에서의 기울기가 되겠지요. 우리는 내려가야 하므로 원래 위치 $x_{i,j}$ 에 기울기를 빼주어 새로운 위치 $x_{i,j+1}$ 을 정하게 됩니다.
그렇다면 $\eta$ 는 무엇일까요? $\eta$ 는 학습률(Learning rate)입니다. 이 하이퍼파라미터(Hyperparameter)는 기울기를 따라 얼마만큼 내려갈지를 결정합니다. 이 값이 너무 작으면 최저점을 찾아가는데 오랜 시간을 필요로합니다. 심한 경우에는 주어진 반복(iteration) 내에서 최저점을 찾지 못하기도 하지요. 반대로 학습률이 너무 크면 최저점을 지나쳐버립니다. 제대로 된 학습을 하지 못하거나 발산해버리는 문제가 발생하지요.
반지름이 1m인 구덩이가 있을 때, 개미와 공룡이 이 구덩이의 최저점을 향해 나아간다고 생각해보겠습니다. 개미가 중심까지 가려면 엄청 오랜 시간이 걸릴 것이고, 공룡은 중심을 지나보지도 못하고 휙 지나쳐 버리겠지요. 아래는 학습률이 너무 작을 때와 클 때 $x_j$ 가 어떻게 변하는지를 보여주는 이미지입니다.
이미지 출처 : srdas.github.io
제대로된 학습을 위해서는 적절한 학습률 찾아야만 합니다. 그렇기 때문에 처음에는 큰 학습률을 사용하다가 점점 줄이는 학습률 감쇠(Learning rate decay) 등의 다양한 전략을 사용합니다. 이곳에서 경사 하강법에 대한 더 자세히 알아볼 수 있습니다.
Comments